Dataset: Drowsy Detection
48×48 face crops • 2 classes • 7,342 images • Kaggle (yasharjebraeily)

Used to validate TEEN-D model replications (MobileNetV2, ResNet18, VGG16).
Used to validate TEEN-D model replications (MobileNetV2, ResNet18, VGG16).
Used to validate Followb1ind1y replications (EfficientNet-B0, MobileNetV3-Large).

Drive&Act defines 34 fine-grained activities. We collapse them into 8 DMS-relevant categories based on the type of driver distraction or behavior they represent.
| Model | Dataset | Published | Ours | Delta |
|---|---|---|---|---|
| TEEN-D MobileNetV2 | Drowsy Det. | 98.99% | 98.99% | 0.00% |
| TEEN-D ResNet18 | Drowsy Det. | 95.28% | 95.28% | 0.00% |
| TEEN-D VGG16 | Drowsy Det. | 97.51% | 97.51% | 0.00% |
| Followb1ind1y EffNet-B0 | StateFarm | 96.85% | 97.43% | +0.58% |
| Followb1ind1y MobNetV3-L | StateFarm | 94.67% | 95.03% | +0.36% |
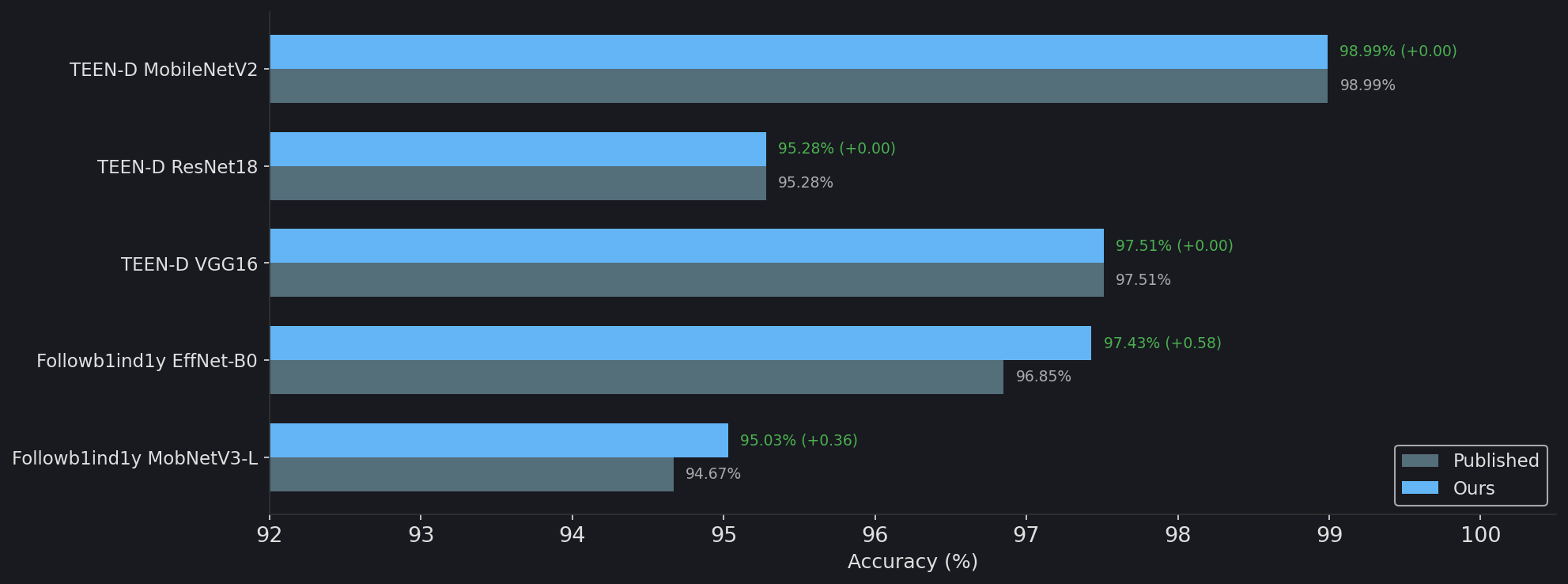
Exact match on drowsy detection. Slight improvement on StateFarm due to minor preprocessing differences. All models evaluated on held-out test splits not seen during training.


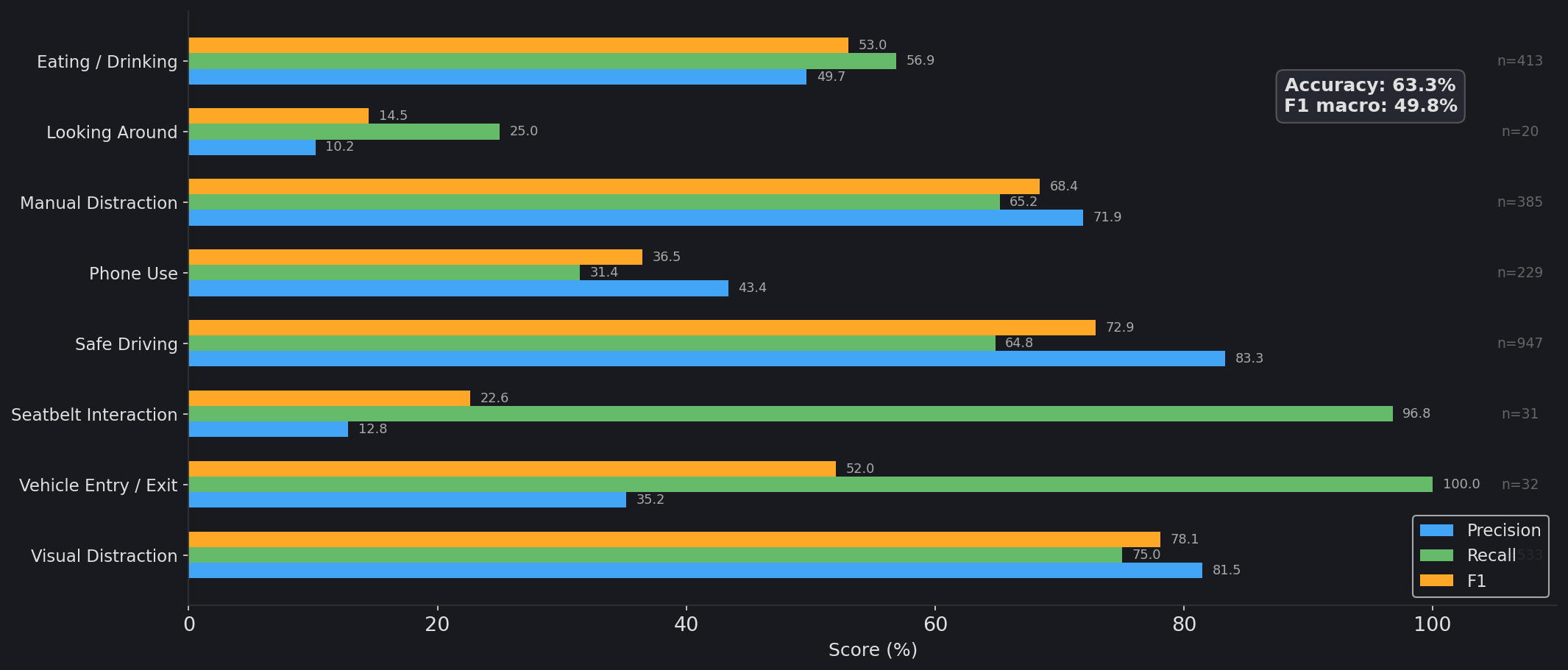
Strong performance on visual_distraction (F1 78.1%) and safe_driving (F1 72.9%). Minority classes (looking_around, seatbelt_interaction) suffer from low support.
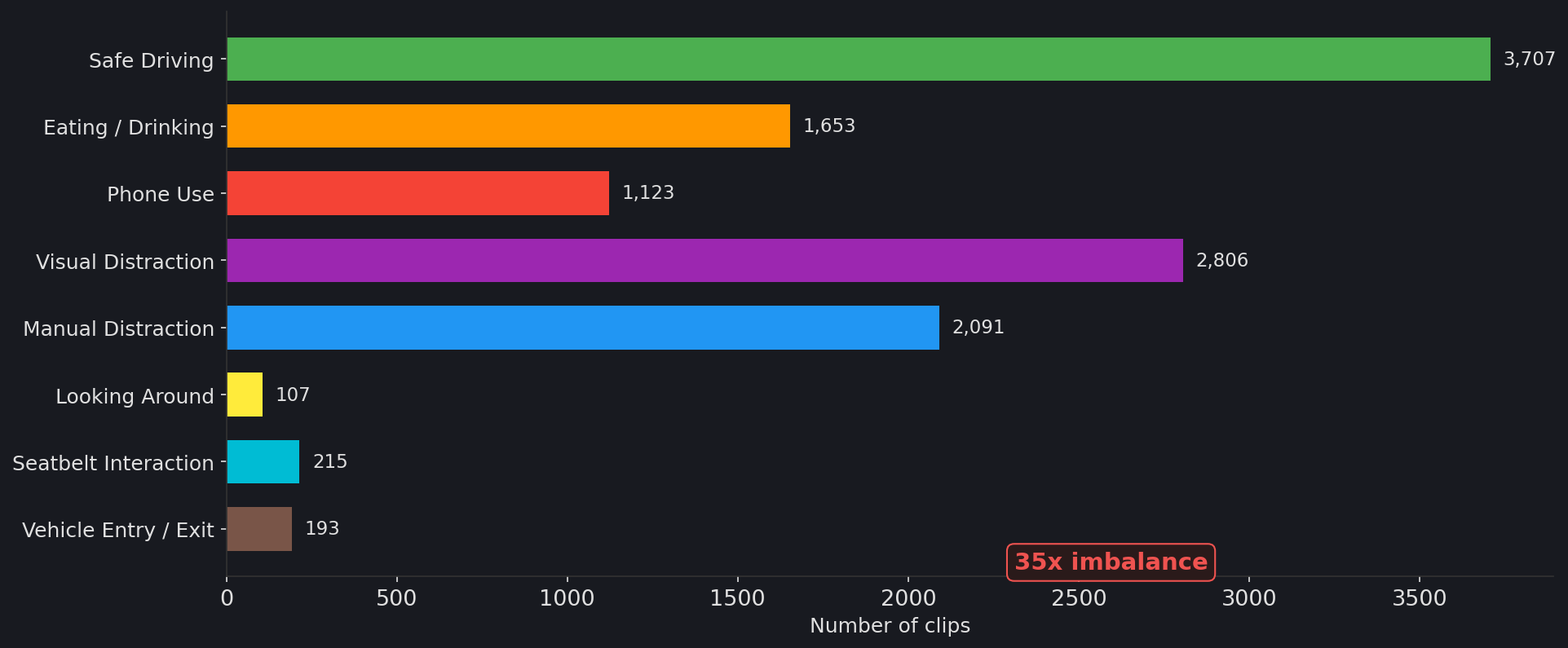
safe_driving dominates at 3,707 clips while looking_around has only 107 (35x imbalance). We use sqrt-inverse-frequency class weighting in the loss function to prevent the model from ignoring minority classes.

NIR frames are extremely dark (88% of pixels below 50/255). CLAHE redistributes contrast, then frames are normalized with ImageNet statistics at full 640×480 resolution.